의미 검색은 LiDAR 와 약간 비슷합니다 . 데이터의 어휘 캐노피를 관통하여 내재된 의미를 드러냅니다. “1부: 기본 파워” 와 “2부: 주요 세부 정보” 에서 FileMaker 의미 검색의 기본 사항을 다루었습니다. 이제 이 새로운 기능이 데이터에 주목을 끌 수 있는 좀 더 이국적인 방법을 고려해 보겠습니다.
자연어를 사용하여 의미 검색을 구성하는 여러 테이블에 걸친 “통합 검색”의 예를 보여드리겠습니다. 그런 다음 이를 두 번째 예로 확장하여 “통합 검색 + 작업”을 보여드리겠습니다. 이 두 가지 예 각각에 대한 다운로드 가능한 데모/튜토리얼 파일이 제공됩니다.
통합 검색
FileMaker에 통합 검색 기능을 구축한 적이 있다면(몇 년 전 제가 사용한 Things 사례 처럼 ), 사용자가 먼저 찾으려는 데이터가 어느 테이블에 있는지 생각하지 않고도 여러 테이블에서 동시에 검색할 수 있는 기능을 제공하는 것이 얼마나 유용한지 이미 알고 있을 것입니다. ( Perform Quick Find비슷한 기능을 하지만 필드 수준에서 수행합니다.)
FileMaker 2024 의 임베딩으로 통합 검색이 더욱 강력해졌습니다. 이 데모에서는 다양한 데이터 테이블에 대한 모든 임베딩이 공유 임베딩 테이블에 저장됩니다. Perform Semantic Find그런 다음 를 통한 의미 검색이 해당 임베딩 테이블에서 수행됩니다.
통합 검색 예
데모 솔루션을 구축했는데, 아래에서 다운로드로 공유하겠습니다. 이 앱은 자산, 사람, 프로젝트의 세 가지 주요 엔터티에 대한 데이터를 관리합니다. 통합 검색을 활성화하고 FileMaker 의미 검색을 사용하도록 구축되었습니다.
“물”을 검색하면 첫 10개 결과가 다음과 같습니다.
- 1개의 자산(서핑에 관한 것으로 설명된 비디오)
- 4개 프로젝트(물과 명확한 연결성 포함)
- 5명(수중조경 및 스쿠버 다이빙과 같은 취미를 가짐)

사용자는 자연어를 사용하여 모든 테이블을 동시에 검색하고, 찾은 결과 집합의 맨 위에 가장 관련성 있는 결과를 볼 수 있습니다. 사용자는 스키마에서 데이터가 어떻게 구조화되어 있는지 예상할 필요가 없으며, 레코드에 입력할 때 텍스트가 구문적으로 어떻게 구조화되었는지에 구애받지 않습니다.
정말 멋지네요. 모든 앱에 대해 이걸 고려하는 게 기대되네요. 이제 몇 가지 배포 고려 사항을 살펴보겠습니다.
저장
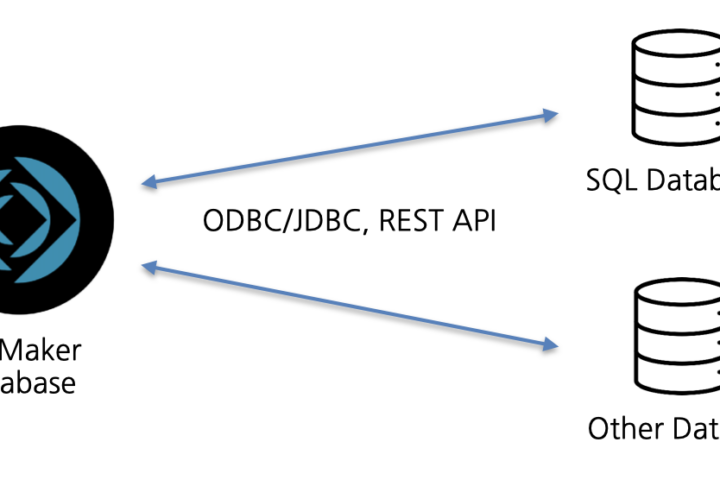
아직 저장소에 대해 언급하지 않았습니다. 임베딩은 공간을 차지합니다. 임베딩의 크기는 임베딩하는 텍스트의 크기가 아니라 선택한 임베딩 모델이 사용하는 차원 수에 따라 결정됩니다. 따라서 모든 임베딩에서 일관된 저장소 공간을 기대해야 합니다. (차원이 1,536개이므로 임베딩당 약 179kb가 표시됩니다.)
임베딩을 컨테이너에 저장하는 것이 가장 좋습니다. 성능이 더 좋고 스토리지가 덜 필요하기 때문입니다. 해당 컨테이너에 외부 스토리지를 사용하여 앱의 스토리지 크기를 작게 유지할 수 있습니다(하지만 아래의 “성능” 섹션을 읽어야 합니다).
여기서 통합 검색이 작용합니다. 모든 임베딩을 단일 테이블에 저장하면 데이터 테이블당 한 번이 아니라 한 곳에서만 외부 저장소를 구성하면 됩니다. 마찬가지로 계산된 코사인 유사도 필드도 한 곳에서만 추가하면 됩니다.
유연성
통합 검색이 어떤 시나리오 에서는 좋을지 몰라도 모든 시나리오에서는 그렇지 않을 수 있습니다 . 예제 파일에서 People 또는 Projects 화면의 컨텍스트에서 수행한 검색을 살펴보세요. 이러한 의미 검색은 공유 Embedding 테이블을 활용하지만 사용자의 컨텍스트는 결과를 단일 데이터 테이블의 레코드로 제한합니다.
먼저 Embedding 테이블에서 수동 찾기 스크립트를 작성하여 찾은 세트를 특정 테이블(예: 모든 활성 프로젝트)의 레코드로 제한한 다음, Perform Semantic Find‘의 “레코드 세트: 현재 찾은 세트” 구성을 사용하여 설정된 레코드 하위 세트 내에서만 검색할 수도 있습니다.
성능
임베딩을 컨테이너로 저장하는 것이 텍스트로 저장하는 것보다 성능이 더 좋다고 언급했습니다. 다른 성능 영향은 어떨까요?
첫째, 컨테이너 임베딩을 외부에 저장하면 컨테이너를 파일에 저장하는 것보다 성능이 느립니다. 하지만 저장 방법에 관계없이 사용자가 레코드를 다운로드할 때 컨테이너 데이터는 레코드에 포함되지 않는다는 점을 기억하세요. 이는 여러 테이블에 임베딩을 추가하면 스토리지가 늘어나기 때문에 중요하지만, 사용자가 임베디드 레코드를 볼 때마다 그 늘어나는 것을 다운로드하는 데 성능 비용을 지불하기를 원하지 않습니다. FileMaker의 컨테이너 스토리지는 이러한 문제에서 우리를 구해줍니다. 컨테이너 데이터는 필요할 때만 다운로드됩니다(예: 의미 검색에 필요할 때).
두 번째로, 그리고 더 일반적으로, 성능이 좋은 의미 검색은 견고한 하드웨어에 의존합니다. 쿼드코어 Intel MacBook Pro에서 테스트해보니 처음에는 빠르게 느껴졌습니다(수백 개 또는 수천 개의 레코드만 있을 때). 하지만 레코드가 50,000개를 넘어가면서 속도가 느려지기 시작했고, 특히 레코드가 100,000개가 넘으면 속도가 느려졌습니다(검색된 레코드 수가 중요하며 , 검색된 테이블에 있는 레코드 수가 중요한 것은 아니라는 점에 유의하세요).
| 검색된 기록 | 첫 번째 검색 | 이후 검색 |
| 50,000 | 22초 | 3초 |
| 75,000 | 35초 | 5초 |
| 100,000 | 124초 | 31~36초 |
쿼드코어 인텔 코어 i7의 로컬 파일
어머나; 그 숫자는 좋지 않아 보입니다. 그리고 지연에 의해 방해받지도 않습니다. 그럼 FileMaker Server에서 호스팅될 때 숫자는 어떨까요?
| 검색된 기록 | 첫 번째 검색 | 이후 검색 |
| 50,000 | 3초 | 3초 |
| 75,000 | 12초 | 3초 |
| 100,000 | 16초 | 3초 |
8코어 M1에 호스팅된 파일
따라서 더 나은 하드웨어가 있는 머신에서 호스팅된 파일은 100,000개의 레코드로 더 성능이 좋고, 50,000개의 레코드로 더 작은 머신에서 로컬 파일이 더 성능이 좋습니다. 안심이 됩니다.
이러한 메트릭은 임베딩 테이블에서 직접 검색하기 위한 것입니다. 위에서 제안한 시나리오에서 관계를 통한 검색으로 직접 검색을 보완하는 것은 어떨까요?(예: 내 레이아웃은 Project 테이블을 기반으로 하지만 각 프로젝트의 임베딩은 관련 임베딩 테이블에 저장됨) 좋지 않습니다. 5,000개 레코드(위에서 설명한 호스팅 머신에서)에서도 220초가 걸렸습니다! 100,000개 레코드에서는 1시간을 기다린 후 프로세스를 종료했습니다.
프로젝트 예제에서, 먼저 프로젝트 관련 임베딩 레코드를 모두 찾아서 성능 문제를 해결할 수 있었습니다. 그런 다음 해당 레코드에 대한 제약 조건으로 의미 검색을 수행한 다음, 필요한 경우 를 사용하여 Go to Related Records프로젝트 테이블을 기반으로 하는 레이아웃으로 돌아왔습니다. 이미 번거롭게 들리지만, 또 다른 복잡한 문제가 있습니다. 해당 프로젝트 레코드에 도달하면 의미 검색의 정렬 순서를 잃어버리게 됩니다. 그래서 이것도 다시 만들어야 합니다.
다시 돌아가서, 통합 검색은 다양한 테이블의 레코드 표현을 하나의 테이블로 모읍니다. 따라서 통합 검색 테이블은 필연적으로 해당 참여 테이블의 레코드 수의 상위 집합으로 성장할 것입니다.
레코드 수가 많으면 성능이 느려집니다.
따라서 통합 검색, 그리고 일반적인 의미 검색의 경우 가능한 최고의 하드웨어가 필요하며, 가능한 경우 검색할 레코드를 제한하는 방법을 현명하게 찾아야 합니다.
튜토리얼/데모 파일
Beezwax Unified Search.fmp12 (26.9MB) 다운로드
- 다운로드에는 FileMaker(.fmp12) 데모 파일, 라이센스 및 README가 포함되어 있습니다.
- 이 데모 파일을 사용하려면 FileMaker 2024(v21.x)가 필요합니다.
- 3부의 데모 파일 과 1부 와 2부의 데모 파일의 경우 , 파일을 사용하려면 사용자의 AI 자격 증명을 제공해야 합니다(오른쪽 상단의 기어 아이콘을 클릭).
- OpenAI에서 제공하지 않은 자격 증명을 사용하는 경우 LLM 임베딩 모델 필드를 구성하고 임베딩 스크립트를 실행해야 합니다(선택한 임베딩 모델과 호환되는 임베딩을 빌드하기 위함).
하지만 잠깐만요, 그게 전부가 아닙니다!…
통합 검색 + 작업
다음 데모에서는 Unified Search 데모를 확장하여 작업 표를 포함합니다. Unified Search의 정신은 사용자가 데이터가 어떻게 구성되어 있는지 생각할 필요가 없다는 것입니다. 작업을 추가하면 한 단계 더 나아갑니다. 사용자는 무언가를 찾는 것과 무언가를 하는 것을 구별할 필요가 없습니다 . Unified Semantic Search를 사용하면 사용자에게 검색어와 관련된 복잡한 옵션 모음을 제공할 수 있습니다.
“AI 모델 설정”을 검색하면 첫 번째 결과는 “AI 구성” 작업입니다.

“이 작업 실행” 버튼을 클릭하면 AI 구성 창이 열립니다.

이 접근 방식의 힘을 반복하자면, 사용자는 무언가를 찾으려고 하는지 아니면 무언가를 하려고 하는지 지정할 필요가 없습니다 . 모든 검색어에 대해 사용자는 데이터 레코드를 검색하거나, 작업을 수행하는 방법에 대한 문서를 검색하거나, 작업 자체에 액세스하려고 할 수 있습니다. 의미론적 검색(그리고 약간의 UX 디자인 사랑)을 통해 앱은 사용자에게 복잡한 결과의 혼합물을 표면화하고 사용자가 자신의 요구를 가장 잘 충족하는 결과를 결정하도록 할 수 있습니다.
위의 예시 작업은 단순히 탐색 스크립트를 실행하는 것입니다. 하지만 조금 더 복잡한 것을 원한다면 어떨까요? 다음으로 “주별 차트”를 검색합니다. 첫 번째 결과는 “사람 차트 보기” 작업인데, 작업 이름에서 “차트”와 의미적으로 유사하고 “사람”이 “주” 필드와 관련이 있다는 것을 이해하기 때문입니다.

해당 작업을 실행하면 주별 인구 수를 나타낸 차트가 생성됩니다.

그럼 여기서 무슨 일이 일어나고 있는 걸까요? 의미 검색에서 “사람 차트 보기” 작업이 나타났지만, 거기서 작업 자체를 하드코딩했습니다.
- 사람 레이아웃으로 이동합니다.
- 모든 기록을 표시합니다.
- 주 필드별로 정렬합니다.
- 주별로 인구 수를 집계합니다.
- 요약된 데이터가 포함된 차트를 표시하려면 카드 창을 엽니다.
검색어에서 차트를 생성하는 것은 멋지지만, 항상 주별로 요약하고 싶다고 가정한다면 그렇지 않습니다(그리고 지원하고 싶은 모든 차트 순열에 대한 작업 기록을 만들고 싶지는 않을 것입니다). 그래서 다음으로 “스포츠별 그래프”를 검색합니다. 의미 검색은 동일한 “사람 차트 보기” 작업을 표면화합니다(이번에는 “차트” 대신 “그래프”를 검색했습니다).

만약 제가 그 액션을 실행한다면(제가 이전에 “주별 차트” 예에서 실행했던 것과 같은 액션), 저는 이 차트를 얻게 되는데, 여기에는 각 스포츠 관련 취미에 참여하는 각 사람의 수가 나와 있습니다.

좋아요, 이제 흥미로워지네요. 그럼 어떻게 그럴까요? 앱은 의미 검색을 사용하여 “사람 차트 보기” 작업을 표면화했습니다. 그런 다음 사용자가 “이 작업 실행” 버튼을 클릭했을 때 앱은 검색어의 의미적 의미를 두 번 더 활용했습니다.
- 스크립트는 검색어 “스포츠별 그래프”와 단어 “취미” 사이의 코사인 유사도를 계산하고 상당한 유사성을 발견했습니다. 그래서 거기에서 취미 중심 요약(상태 중심 요약 대신)으로 분기되었습니다.
- 스크립트는 취미 기록 표에서 의미 검색을 수행하여 검색어와 높은 코사인 유사성을 가진 취미를 찾았고, 대략 “스포츠”와 관련된 취미를 찾았습니다.
즉, “스포츠별 그래프”라는 검색어가 세 가지의 뚜렷한 의미 비교에 활용되었음을 의미합니다.
- “사람별 차트” 작업 기록을 찾으려면
- 차트가 취미 분야를 기반으로 해야 한다는 것을 결정했습니다.
- 차트에 포함할 구체적인 취미를 확인하세요.
저는 앞서 사용자가 무언가를 찾고 싶어할 수도 있고 … 혹은 무언가를 하고 싶어할 수도 있다고 말씀드렸습니다 . 하지만 “스포츠별 그래프”라는 검색어가 두 가지 모두를 지원하는 방식에 주목하세요. 사용자가 취미( 무언가를 하는 것) 차트를 생성할 수 있었지만, 스포츠 취미(무언가를 찾는 것) 를 가진 특정 하위 집합의 사람들만 포함했습니다 . 사용자가 원하는 대로 자신의 필요를 입력할 수 있고, 사용자가 수행하고자 하는 작업과 관련이 있는 검색어의 부분과 사용자가 찾고자 하는 데이터와 관련이 있는 검색어의 부분을 분석하는 부담이 앱으로 분산된다는 점이 얼마나 멋진지요.
2부 에서 제가 언급한 요점을 반복하자면 , 이것이 이런 차트에 도달하는 유일한 방법 이어서는 안 됩니다 . 사용자는 여전히 앱의 동작에 액세스할 수 있는 모호하지 않은 방법이 필요합니다.
튜토리얼/데모 파일
Beezwax Unified Search + Actions.fmp12 (28.2MB) 다운로드
- 다운로드에는 FileMaker(.fmp12) 데모 파일, 라이센스 및 README가 포함되어 있습니다.
- 이 데모 파일을 사용하려면 FileMaker 2024(v21.x)가 필요합니다.
- 3부의 데모 파일 과 1부 와 2부의 데모 파일의 경우 , 파일을 사용하려면 사용자의 AI 자격 증명을 제공해야 합니다(오른쪽 상단의 기어 아이콘을 클릭).
- OpenAI에서 제공하지 않은 자격 증명을 사용하는 경우 LLM 임베딩 모델 필드를 구성하고 임베딩 스크립트를 실행해야 합니다(선택한 임베딩 모델과 호환되는 임베딩을 빌드하기 위함).
대조군 대 시험군
화려한 스크립팅과 레이아웃 아래에 FileMaker 앱은 뼈대로 데이터베이스를 가지고 있습니다. 데이터베이스의 역할은 데이터를 구조화하는 것이고, 그 데이터를 이해하지 않고도 그렇게 할 수 있습니다. 특히, 큰 텍스트 문자열이 포함된 필드에 대해 이야기할 때, 데이터를 이해하는 부담은 전통적으로 사용자에게 있습니다.
이 블로그 시리즈 전반에 걸쳐 저는 의미 검색이 사용자가 데이터가 어떻게 표현되었는지 알거나 기억할 필요가 없도록 해준다고 강조했습니다. 왜냐하면 우리는 문자열의 의미를 검색하고 있지, 문자열에 있는 문자나 문자가 아니기 때문입니다. 다시 말해, 의미 검색은 사용자가 이해하는 문자열(자신의 검색어)을 활용하여 반드시 이해하지 못하는 문자열(사용자가 텍스트가 어떻게 표현되었는지 모를 수 있다는 의미에서)을 찾을 수 있도록 해줍니다.
하지만 1부의 이력서 예시를 떠올려보면 , 사용자의 검색어는 사용자에게 익숙 하지 않은 문자열 (후보자의 이력서)이었고, 발견된 레코드는 사용자 에게 익숙 했을 법한 문자열 (엄선된 구인 공고)이었습니다. 따라서 일반적으로 의미 검색을 사용하여 레코드를 찾는 반면, 의미 검색이 검색어 자체의 의미를 이해하는 데 어떻게 도움이 될 수 있는지 살펴보겠습니다. (그리고 이 예시에서는 검색어를 “검색어”라기보다는 “입력”이라고 생각해야 합니다.)
고객이 기후 기술 부문에서 일한다고 가정해 보겠습니다. 고객은 자신의 분야와 관련된 학술 논문을 검토하고 싶어하는데, 논문이 관련성 있는 방식으로 태그되지 않았거나 다른 분야에 게재된 논문이더라도 마찬가지입니다. 고객이 모든 주제에 대한 모든 논문을 읽을 것으로 기대할 수는 없습니다. 그러면 FileMaker 앱이 어떻게 도움이 될 수 있을까요?
먼저, 클라이언트는 FileMaker 앱에서 각 초점 영역과 관련이 있는 것으로 이미 알려진 논문의 하위 집합을 식별합니다. 이 예에서 클라이언트는 100개의 논문에 ” 직접 공기 포집 “이라는 태그를 붙입니다. 이를 통제 그룹이라고 부르겠습니다.
두 번째로, 우리는 통제 그룹이 유사한 주제를 가진 논문으로 구성되어 있는지 확인하고 싶습니다. 통제 그룹의 각 논문의 제목+초록에 임베딩을 구축한 다음, 모두 서로 비교하여 점수를 매깁니다. 어떤 논문이든, 우리는 의미 검색을 수행하여 해당 논문과 ≥ .8 코사인 유사성을 가진 “직접 공기 포집” 태그가 있는 논문을 찾아 점수를 도출합니다. 우리는 항상 자신과 최대 99개의 다른 논문을 찾을 것으로 예상하여 1~100 범위의 점수를 얻습니다. 여기서 100은 해당 논문이 100개의 “직접 공기 포집” 논문 모두와 최소 80% 유사함을 의미합니다.

여기서 저는 가장 낮은 점수(95%)를 받은 대조군을 맨 위에 정렬했습니다. 대부분의 논문은 100%를 받았습니다. 따라서 대조군이 실제로 밀접하게 관련된 논문으로 구성되어 있다는 것을 재확인합니다. 저는 제목에 “직접적인 공기 포집”이 포함되지 않았지만 제목에 해당 문자열이 포함된 대조군의 5개 논문보다 높은 점수를 받은 기록을 강조했습니다.
셋째, 테스트 그룹을 추가하고 싶습니다. 이는 클라이언트가 읽지 않은 논문이므로 “직접적인 공기 포집”과 관련이 있는지 알 수 없습니다. 50개의 논문을 삽입하고 통제 그룹과 동일한 의미적 비교를 요청합니다(테스트 그룹의 논문은 통제 그룹의 논문과 관련이 없을 수 있으므로 0~100점 범위에서 채점됩니다).

왼쪽에는 테스트 그룹의 50개 논문과 그들의 점수가 나와 있습니다. “화석 연료로 구동되는 질소 변환을 넘어서”는 19%에 불과한 점수를 받았습니다(즉, 대조군의 100개 논문 중 19개와 80% 유사하다는 의미). 따라서 엉터리입니다. 하지만 “바이오매스 기반 화학 루핑 기술: 좋은 점, 나쁜 점, 그리고 미래”는 96%를 받았습니다! 이는 승자이며, 인간의 검토를 받을 만합니다.
따라서 이러한 논문이 게시된 디지털 저장소를 마이닝하고, 의미 검색을 사용하여 관심 있는 주제와 관련된 새로운 논문의 관련성을 평가하고, 가장 높은 점수를 받은 논문을 고객에게 표시하는 자동화된 프로세스를 상상해 보세요. 실제로 우리 앱은 방대한 양의 자료를 훑어보고, 가장 관련성 있는 논문만 검토하도록 고객을 귀찮게 할 것입니다. 고객이 가장 유망한 논문에만 시간을 집중할 수 있을 때 절약되는 시간을 생각해 보세요.
앱은 거기서 멈출 필요가 없습니다. 의미 검색을 사용하여 하위 주제(예: “흡착 물질”)를 계층화할 수 있습니다. 그리고 기존 Insert from URLAI 통합을 사용하여 감정 분석(“논문이 직접 공기 포집을 어떻게 묘사하는가”), 주제 영역 분석 및 논문에 대한 기타 심층 분석을 추가할 수 있습니다. 학술 논문이든, 연구 논문이든, 일반적인 논문이든, 심지어 더 광범위하게 새로운 정보가 데이터에 어떻게 들어맞는지 이해해야 하는 모든 종류의 분석이든, 의미 검색이 도울 준비가 되어 있습니다.
명확히 하자면, 이 기술은 모델을 훈련하는 것과 같지 않습니다. 이 앱은 실제로 “직접적인 공기 포집”에 대해 아무것도 이해하지 못하며, 데이터에 대한 다른 질문에 답할 준비가 되어 있지 않습니다. 그러나 우리의 목적을 위해, 이 앱은 논문의 초록을 “읽고” 그것이 우리의 관련성 기준을 충족하는지 여부를 결정할 수 있습니다.
이 시나리오를 제게 알려주시고, 모든 논문에 대한 링크를 제공해 주신 제 친구 존 콘웰에게 감사드립니다.
이 아이디어를 시각화하려면 Michael Wallace의 의미 검색 3D 모델을 확인하세요 . 특히 10:59 지점에서요. 이 모델을 통해 테스트 기록과 대조군 간의 지리적 관계를 볼 수 있습니다. 정말 멋지네요.
요약
솔루션에 FileMaker 의미 검색을 추가하고 싶지만, 노력에 대해 확신이 없다면 좋은 소식이 있습니다. 500개 레코드에 대한 임베딩을 만드는 것을 포함하여 가장 간단한 구현에서 5분 밖에 걸리지 않습니다. 정말 빠릅니다. 앱의 검색에 요정 가루를 뿌려 날리게 하는 것과 같습니다. 너무 쉬워서 거의 속임수를 쓰는 것 같습니다.
의미론적 검색은 앱의 핵심 기능인 데이터 검색을 강화합니다. 이제 사용자는 원하는 데이터를 자신의 말로 요청할 수 있으며, 앱은 사용자가 무엇을 찾고 있는지 (더 잘) 이해할 수 있습니다. 데이터는 어둠 속에서 사라지므로 의미론적 검색이 불을 켜게 하세요.
FileMaker 2024 의미 검색 – 참조 블로그 게시물
스테인드글라스 아트 © 2024 Uma Kendra , 허가를 받아 사용함.